Анализ текстовой релевантности
- Исключение навигационных блоков, стоп-слов и других нерелевантных элементов
- Анализ одного или нескольких сайтов-конкурентов
- Работа без привязки к региону и поисковой системе
- Гибкая фильтрация данных по множеству параметров
- Анализ униграмм, биграмм и триграмм с поиском отсутствующих терминов
- Сравнение вашего сайта с конкурентами по различным SEO-параметрам
- Анализ структуры страницы
- Определение объёма релевантного текстового слоя
- Выявление уникальных ключевых терминов
- Подсчёт заголовков H2, H3 и H4
- Анализ количества смысловых блоков
- Определение блоков с ключевым ядром
- Поиск уникальных терминов ядра внутри блока
- Анализ концентрации ключевого ядра в каждом блоке
Анализ текстовой релевантности
Сравнение вашей страницы с лидерами поиска.
Сущности, Интенты, Смысловая модель, Униграммы и т.д.
❓ Часто задаваемые вопросы
Что такое анализ текстовой релевантности и как работает сервис?
Анализ текстовой релевантности — это оценка того, насколько содержание страницы соответствует устойчивой смысловой модели ниши.
Сервис сравнивает вашу страницу с конкурентами и выявляет, какие термины, смыслы и структуры являются стандартом рынка.
🧠 Как работает анализ
Система проходит несколько этапов:
- очищает HTML от мусора (скрипты, стили, навигация)
- выделяет текст и разбивает его на слова и фразы
- приводит слова к начальной форме (лемматизация)
- сравнивает частоты слов с конкурентами (TF-IDF)
- строит модель «нормы» для вашей ниши
📊 Что именно анализируется
- Охват темы — какие термины используются в нише
- Глубина — насколько подробно раскрыты ключевые слова
- Структура — как распределён контент по блокам
- Анкор-лист — какие слова используются в ссылках
📦 Пример
Допустим, анализируется тема «SEO продвижение сайта».
У конкурентов часто встречаются:
- «технический аудит»
- «сбор семантики»
- «внутренняя оптимизация»
- «линкбилдинг»
Если на вашей странице этих терминов нет — сервис покажет их как отсутствующие.
Если они есть, но используются слабо — попадут в рекомендации по глубине.
🎯 Что вы получаете
- список недостающих терминов
- рекомендации по усилению текста
- понимание структуры идеальной страницы
- сравнение с конкурентами
⚠ Важно понимать
Сервис анализирует не просто слова, а смысловые единицы и закономерности рынка.
Это не генератор текста, а инструмент для построения правильной модели страницы.
Проще говоря:
- конкуренты → формируют модель ниши
- ваша страница → сравнивается с этой моделью
- результат → список, что добавить и усилить
Как сервис строит смысловую модель ТОПа?
Смысловая модель ТОПа — это модель страницы, построенная на основе конкурентов. Она помогает анализировать не только слова, но и то, как рынок раскрывает тему: какие сущности использует, какие вопросы закрывает, какие блоки страницы считает важными и насколько ваша страница похожа на общий интент выдачи.
Модель нужна, чтобы рекомендации были не в формате «добавьте слово X», а в формате понятных действий: добавить блок, раскрыть вопрос, переписать секцию, отделить нерелевантный контент или усилить смысловой фокус страницы.
Проще говоря: конкуренты формируют рыночную норму, ваша страница сравнивается с этой нормой, а сервис показывает, где есть смысловые разрывы.
Как считается
- берётся HTML вашей страницы и HTML конкурентов;
- страницы очищаются от технического мусора, скриптов, стилей и лишних блоков;
- из текста извлекаются сущности, вопросы, заголовки, структура и паспорт страницы;
- для документов и вопросов считаются embedding-векторы;
- система сравнивает вашу страницу со средней моделью конкурентов и отдельными конкурентами;
- на основе разрывов собираются объяснения и план правок.
Как читать план «Что исправить на странице»?
Это приоритетный план SEO-правок, собранный из всех смысловых сигналов: вопросов, сущностей, структуры, паспорта страницы и cosine similarity.
В таблице показывается не только что добавить, но и как работать с правкой: тип правки, рекомендуемый блок, пример H2/H3, место на странице и причина.
Как читать этот блок
- Тип правки — добавить блок, переписать блок, добавить FAQ или убрать нерелевантный контент.
- Куда на странице — где логично разместить новый смысл: после описания услуги, перед CTA, рядом с формой или в FAQ.
- Рекомендуемый H2/H3 — пример заголовка, который закрывает найденный gap.
- Что сделать — конкретная задача для редактора, SEO-специалиста или владельца сайта.
- Почему — какой сигнал ТОПа привёл к этой рекомендации.
Цель блока — превратить аналитику в план редактирования страницы, а не оставить пользователя с набором сырых метрик.
Как считается
- система берёт найденные gaps из сущностей, вопросов, структуры, паспорта и cosine similarity;
- каждому gap присваивается приоритет: важно, средне или низко;
- вопросные gaps превращаются в H2/H3 или FAQ-ответы;
- структурные gaps превращаются в задачу добавить или переписать блок;
- entity gaps превращаются в задачу раскрыть сущность через пример, этап, риск, цену или критерий выбора;
- topic drift превращается в задачу убрать или отделить смежные карточки от основного контента.
Откуда берутся причины в блоке «Почему система так решила»?
Этот блок объясняет, почему сервис предложил те или иные правки. Он показывает не только проблему, но и доказательство: какой слой анализа сработал, какой статус у сигнала, что найдено у конкурентов и почему это важно.
В отличие от блока «Что исправить», здесь акцент не на задаче, а на причине. Это помогает проверить логику системы и понять, стоит ли принимать рекомендацию.
Какие слои могут попадать в объяснение
- Частотность сущностей — важная сущность есть у конкурентов, но отсутствует или слабо раскрыта у вас.
- Покрытие вопросов — в ТОПе есть вопрос, на который ваша страница не отвечает прямо.
- Структура — у конкурентов есть смысловой блок, которого нет у вас, или он раскрыт иначе.
- Фокус страницы — в паспорт страницы попали соседние темы, которые размывают основной интент.
- Косинусное сходство документов — общий смысл страницы отличается от средней модели ТОПа.
Колонка «Сигнал у конкурентов» показывает, на что именно опирается вывод: вопрос из ТОПа, фрагмент паспорта, предложение конкурента или процент сходства.
Как считается
- для каждого gap сохраняется слой анализа: сущности, вопросы, структура, фокус или embeddings;
- сохраняется статус: смысл совпадает, частично, нет у вас или разный смысл;
- для вопросов считается ближайшее совпадение на вашей странице;
- для сущностей считается частота у вас, медиана ТОПа и присутствие у конкурентов;
- для структуры сравниваются секции паспортов вашей страницы и конкурентов;
- для доказательства подставляется сигнал конкурентов: вопрос, предложение, фрагмент паспорта или процент сходства.
Как сравнивается паспорт вашей страницы с конкурентами?
Паспорт страницы — это краткое смысловое описание страницы после очистки HTML. Сервис пытается понять, что это за страница, как она работает, какую проблему закрывает, что получает пользователь и какие ключевые блоки присутствуют.
В сравнении «ваша страница vs конкуренты» показывается, какие смысловые блоки есть у вас и какие похожие блоки выделены у конкурентов. Колонка конкурентов — это сводка по ТОПу, а не текст одного конкретного сайта.
Зачем нужен паспорт
Он помогает увидеть различие не на уровне слов, а на уровне смысла. Например, у вас может быть блок «Как работает», но по содержанию он говорит о выгодах, а у конкурентов этот блок раскрывает этапы, сроки, ответственность и результат.
Поэтому статус «частично» или «разный смысл» не означает, что заголовка нет. Он означает, что блок есть, но раскрывает не тот набор смыслов, который характерен для ТОПа.
Как считается
- из каждой страницы берутся title, meta description, H1-H3 и сильные текстовые блоки;
- технические, cookie, modal, hidden и навигационные шумы по возможности отсекаются;
- текст группируется по смысловым секциям: что это, как работает, что анализирует, какую проблему закрывает, что получает пользователь;
- для каждой секции собираются фрагменты конкурентов;
- если секция есть у конкурентов, но не выделена у вас, ставится статус «нет у вас»;
- если секция есть у вас и у конкурентов, считается semantic similarity между текстом вашей секции и сводкой ТОПа.
Какие сущности рынок считает важными?
Частотность сущностей показывает, какие важные понятия повторяются у конкурентов: услуги, методы, характеристики, цены, риски, критерии выбора, бренды или объекты ниши.
Это не обычный список слов для механической вставки. Сущность нужно раскрывать как смысл: объяснить её роль, привести пример, показать этап работы, риск, условие применения или критерий выбора.
Как сущность попадает в таблицу
- термин встречается у конкурентов;
- имеет заметную медианную частоту в ТОПе;
- присутствует у достаточной доли конкурентов;
- отсутствует или заметно слабее раскрыт на вашей странице.
Строгие пропуски важнее для правок. Слабые сигналы нужны для ручной проверки: иногда это полезная тема, а иногда бренд, пункт меню или особенность отдельного конкурента.
Как считается
- текст конкурентов токенизируется и приводится к нормальной форме через лемматизацию;
- считается частота терминов у каждого конкурента;
- для каждой сущности считается медиана частоты по ТОПу;
- считается присутствие: у какой доли конкурентов встречается сущность;
- сравнивается частота на вашей странице с медианой ТОПа;
- importance растёт, если сущность часто встречается у конкурентов, присутствует у значимой доли ТОПа и отсутствует или слабее раскрыта у вас.
На какие вопросы ТОПа отвечает ваша страница?
Покрытие вопросов показывает, какие вопросы встречаются у конкурентов и насколько ваша страница отвечает на них по смыслу.
Сервис извлекает вопросы из H-заголовков, FAQ, списков и текстовых блоков конкурентов, затем сравнивает их с вопросами и заголовками вашей страницы через смысловое сходство.
Как читать статусы
- Смысл совпадает — вопрос хорошо закрыт на вашей странице.
- Частично — похожий смысл есть, но ответ не прямой или не полностью раскрытый.
- Нет у вас — вопрос встречается в ТОПе, но на странице нет сильного ответа.
Если вопрос важный, его лучше закрывать отдельным H2/H3 или FAQ-ответом, а не прятать внутри общего абзаца.
Как считается
- из конкурентов извлекаются вопросы из H-заголовков, FAQ, списков, summary, dt и текстовых блоков;
- шумные и слишком длинные формулировки фильтруются;
- такие же вопросные формулировки извлекаются с вашей страницы;
- для вопросов конкурентов и вашей страницы строятся embedding-векторы;
- для каждого вопроса ТОПа ищется ближайший вопрос или заголовок на вашей странице;
- по similarity выставляется статус: смысл совпадает, частично или нет у вас.
Насколько ваша страница близка к интенту ТОПа?
Косинусное сходство документов сравнивает embedding-вектор вашей страницы с векторами конкурентов и средней моделью ТОПа. Это показывает общий тематический фокус страницы, а не частоту отдельных слов.
Высокий процент означает, что страница в целом находится в том же интенте, что и конкуренты. Низкий процент может означать, что страница раскрывает соседнюю тему, смешивает несколько услуг или использует структуру, не похожую на ТОП.
Как читать значения
- 82% и выше — общий интент хороший, нужно чинить точечные разрывы.
- 70–81% — тема похожа, но часть структуры или смыслов отличается.
- ниже 70% — есть риск ухода в соседний интент; сначала проверяется фокус страницы.
Если средняя модель ТОПа высокая, а отдельные вопросы или сущности missing, страницу не нужно переписывать полностью. Нужно доработать конкретные блоки, которые указаны в плане действий.
Как считается
- из вашей страницы и конкурентов собирается очищенный текст;
- для каждого документа строится embedding-вектор;
- вектор вашей страницы сравнивается с каждым конкурентом через cosine similarity;
- отдельно считается средний вектор ТОПа и сходство вашей страницы с этой рыночной моделью;
- также выделяется ближайший конкурент — страница с максимальным similarity;
- результат показывает общий тематический фокус, а не совпадение отдельных слов.
Почему рядом со словом стоит бейдж «сущность»?
В таблице униграмм часть слов помечается бейджем «сущность». Это значит, что слово совпало с одной из сущностей смысловой модели ТОПа.
Формула простая: если термин из таблицы униграмм найден в списке сущностей ТОПа, строка получает метку, категорию, присутствие у конкурентов и importance.
Такая метка помогает отличать обычные частотные слова от понятий, которые могут быть важны для раскрытия интента страницы.
Важно: бейдж «сущность» не означает, что слово нужно просто добавить в текст. Сущность нужно раскрывать смыслом: через пример, объяснение, этап работы, ограничение, цену, риск или критерий выбора.
Как считается
- таблица униграмм строится из нормализованных однословных терминов;
- смысловая модель ТОПа отдельно формирует список сущностей ТОПа;
- если слово из униграмм совпадает с сущностью из модели, строка получает бейдж;
- в бейдж добавляется категория сущности, присутствие у конкурентов и importance;
- если слово не попало в список сущностей, оно остаётся обычным unigram-термином без бейджа.
Зачем в таблицах появились полосы процентов?
Полосы процентов — это быстрый визуальный индикатор силы сигнала. Они помогают не читать каждую цифру отдельно, а быстро понять, где показатель высокий, средний или слабый.
В разных блоках полосы означают разные вещи:
- в сущностях — долю конкурентов, у которых встречается сущность;
- в вопросах — смысловое сходство вопроса ТОПа с вашей страницей;
- в документах — cosine similarity между страницей и конкурентами или моделью ТОПа.
Полоса не заменяет текстовую рекомендацию. Она нужна для быстрого сканирования, а решение принимается по связке: статус, сигнал конкурентов, пояснение и план действий.
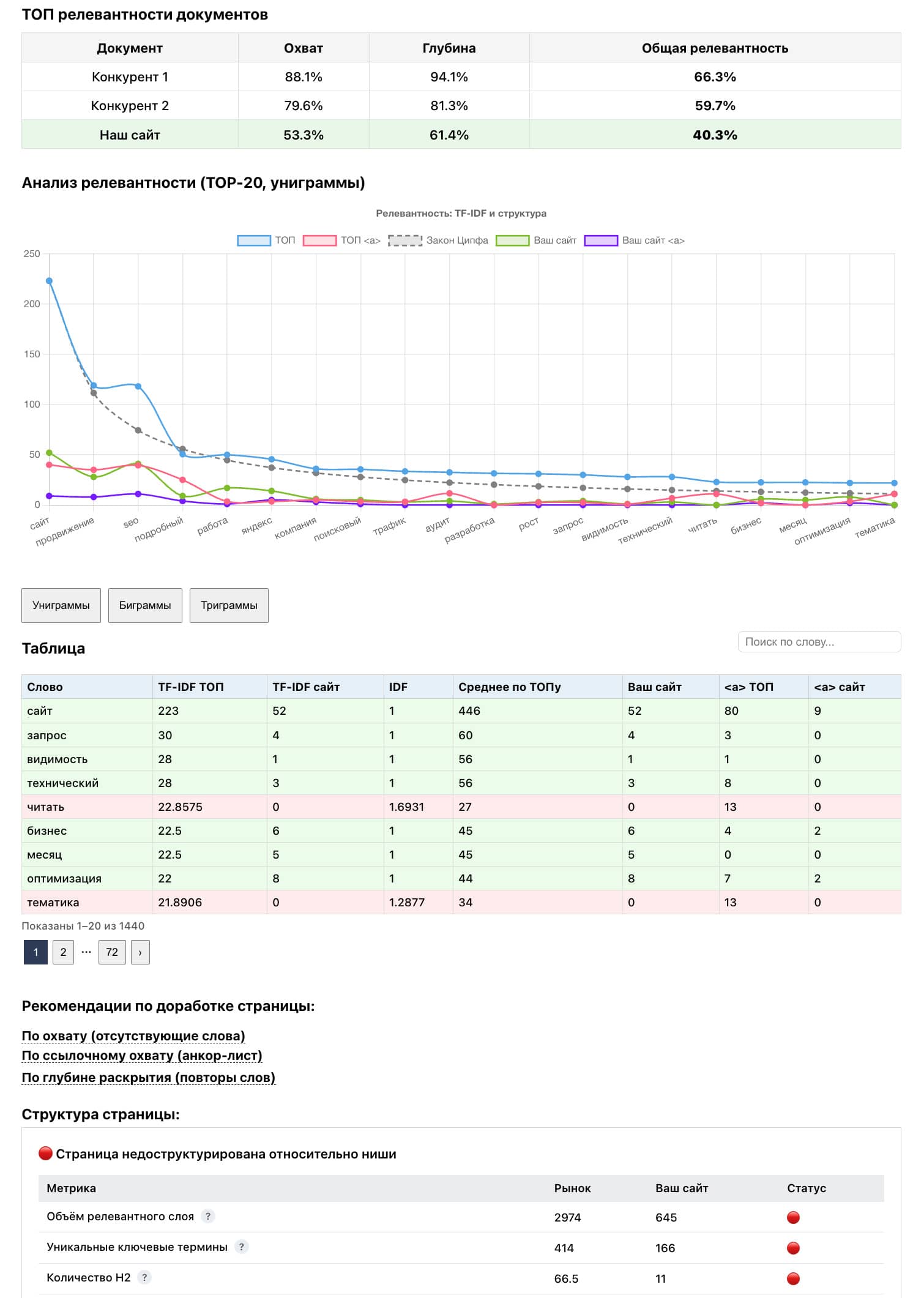
Как рассчитывается релевантность страницы?
Алгоритм строит сравнительную модель на основе нескольких конкурентов.
Учитывается:
- частота употребления терминов,
- их значимость внутри темы,
- стабильность использования у разных игроков рынка,
- и глубина раскрытия смыслов.
Итоговая релевантность — это баланс тематического охвата и степени проработки ключевых терминов.
Что означает «по охвату» и «по глубине»?
По охвату — это термины и смысловые элементы, которые присутствуют у большинства конкурентов, но отсутствуют на вашей странице.
По глубине — это степень раскрытия уже используемых терминов: насколько полно и интенсивно они представлены по сравнению с устойчивой моделью рынка.
Это позволяет не просто добавить слова, а выстроить более целостное и экспертное раскрытие темы.
Зачем нужен фильтр «Минимальное присутствие у конкурентов»?
Фильтр позволяет учитывать только те термины, которые встречаются у определённой доли конкурентов (например, у 50%, 75% или 100%).
Это помогает выделить устойчивое ядро ниши и исключить случайные слова, характерные только для отдельных сайтов.
Сколько конкурентов лучше использовать в анализе?
Количество конкурентов напрямую влияет на строгость формируемой семантической модели.
2 конкурента — модель более мягкая.
В словарь попадает больше терминов, включая вариативные
и менее устойчивые элементы.
7 конкурентов — модель более строгая.
Учитываются только устойчивые термины,
повторяющиеся внутри конкурентного поля.
Чем больше конкурентов участвует в анализе, тем уже и «чище» становится тематическое ядро — остаются только структурно значимые элементы ниши.
Что выбрать?
- Если задача — выделить устойчивое ядро рынка, лучше использовать 7 конкурентов.
- Если задача — собрать максимум идей, расширить вариативность формулировок и увидеть больше семантических направлений, подойдут 2 конкурента.
Почему при увеличении количества конкурентов семантика уменьшается?
При добавлении новых конкурентов модель становится более строгой.
Сервис формирует устойчивую смысловую модель ниши на основе пересечения терминов и структурных элементов. Чем больше сайтов участвует в анализе, тем выше требования к устойчивости слова.
Если термин встречается только у одного или двух конкурентов, он считается вариативным или ситуативным. При добавлении новых сайтов такие элементы естественным образом отсеиваются.
В результате:
- уменьшается количество случайных слов;
- сужается тематическое поле;
- формируется более чистое и устойчивое ядро ниши.
Проще говоря:
- 2 конкурента → модель мягкая, семантики больше;
- 7 конкурентов → модель строгая, остаётся только устойчивое ядро.
Это нормальное поведение системы — она не «теряет» слова, а очищает модель от нестабильных элементов.
Почему при фильтре 50% количество ключей почти не меняется?
Фильтр «Минимальное присутствие у конкурентов» влияет на модель не линейно.
При значении 50% система оставляет только те слова, которые встречаются минимум у половины конкурентов. Однако в большинстве ниш ключевые термины и так повторяются у 2–3 сайтов.
Поэтому при переходе от «Без фильтра» к «50%» визуально количество ключей может не измениться — потому что значимая часть слов уже соответствует этому условию.
Существенные изменения становятся заметны при фильтре 75% или 100%, когда в модель попадают только устойчивые, повторяющиеся у большинства конкурентов элементы.
Проще говоря:
- 50% — мягкая фильтрация (удаляет только случайные слова)
- 75% — формирует ядро ниши
- 100% — оставляет только максимально устойчивые элементы
Это нормальное поведение модели и признак того, что в нише уже есть сформированная семантическая структура.
Нужно ли учитывать навигационное меню при анализе?
В 90% случаев меню лучше исключать из основного анализа.
🎯 В чём проблема навигации
Навигационные блоки (menu, header, footer):
- дублируются на всех страницах сайта
- часто повторяются дважды (desktop + mobile)
- содержат множество несвязанных разделов
- не отражают смысл конкретной анализируемой страницы
Например, при анализе страницы «SEO продвижение сайта» в меню могут присутствовать:
- Разработка сайтов
- Контекстная реклама
- SMM
- Таргетинг
- Блог
- Кейсы
Эти слова начинают влиять на:
- оценку тематического охвата
- глубину использования терминов
- распределение веса n-грамм
- формирование устойчивого ядра
Но они относятся к структуре сайта, а не к содержанию страницы.
🚨 Чем это искажает модель
Включённое меню может:
- размывать тематическое ядро
- создавать ложные устойчивые пересечения между конкурентами
- искусственно усиливать второстепенные направления
- снижать точность анализа глубины раскрытия темы
Особенно это критично для агентств и крупных сайтов с объёмной навигацией.
🟢 Когда меню учитывать имеет смысл
- при анализе архитектуры сайта
- при исследовании стратегии перелинковки
- при моделировании общей структуры бизнеса
Но для анализа одной посадочной страницы меню чаще является шумом.
🏆 Как работает сервис
Сервис позволяет исключить навигационные блоки из анализа.
По умолчанию рекомендуется анализировать именно контент страницы, так как сервис сравнивает страницу с устойчивой смысловой моделью рынка, сформированной на основе конкурентов.
Ключевая мысль:
Меню — это структура сайта.
Контент — это смысл страницы.
Сервис анализирует именно смысл.
Что означает блок «Структура страницы»?
Это количество значимых терминов рыночного ядра, которые реально используются на странице.
Метрика показывает, насколько полно страница охватывает тематику ниши.
Если показатель ниже рынка, это означает, что страница раскрывает меньше направлений и подтем.
Что делать:Добавить новые смысловые блоки: «Этапы SEO-продвижения», «Коммерческие факторы», «Поведенческие сигналы», «Продвижение в Яндексе и Google», «Локальное SEO», «Продвижение интернет-магазинов».
Что означают «Уникальные ключевые термины»?
Это количество разных терминов ядра, использованных на странице.
Метрика отражает ширину тематического покрытия — насколько разнообразно раскрывается ниша.
Что делать:Не повторять «продвижение сайтов» 50 раз. Добавлять вариации: «SEO-аудит», «сбор семантики», «кластеризация», «линкбилдинг», «техническая оптимизация», «краулинговый бюджет», «CTR в поиске».
Что показывает количество H2?
Это количество основных смысловых разделов страницы.
Что делать:Добавить 3–5 крупных разделов: «Сроки продвижения», «Стоимость SEO», «Гарантии и KPI», «Частые ошибки в SEO».
Что означает количество H3?
Это уровень детализации внутри основных разделов.
Что делать:В разделе «Этапы продвижения» добавить H3: «Анализ конкурентов», «Технический аудит», «Контент-стратегия», «Внешняя оптимизация».
Насколько важны H4?
H4 отражают микро-детализацию контента.
Что делать:Использовать H4 для конкретики: «Оптимизация мета-тегов», «Настройка robots.txt», «Оптимизация скорости загрузки».
Что означает показатель «H3 на один H2»?
Это коэффициент глубины раскрытия разделов.
Что делать:Если H2 есть, но внутри почти нет подразделов — раздел нужно детализировать, а не оставлять поверхностным.
Что показывает «Количество смысловых блоков»?
Это число логических сегментов страницы.
Что делать:Добавлять отдельные блоки: «Преимущества работы с нами», «Кейсы продвижения», «FAQ по SEO», «Частые ошибки клиентов».
Что означает «Блоков с ключевым ядром»?
Это количество блоков, которые действительно содержат тематическое ядро ниши.
Что делать:Убедиться, что каждый раздел несёт SEO-смысл, а не является декоративным. Например, вместо абстрактного «О компании» сделать блок «Опыт продвижения сайтов в конкурентных нишах».
Что значит «Уникальные термины ядра в блоке»?
Это показатель насыщенности каждого смыслового блока.
Что делать:В разделе «Продвижение сайтов» добавить подаспекты: «SEO для услуг», «SEO для e-commerce», «Продвижение по трафику», «Продвижение по лидам».
Что показывает «Концентрация ядра в одном блоке»?
Это распределение ключевых терминов по структуре страницы.
Метрика отвечает на вопрос: страница построена вокруг одного сильного раздела или равномерно раскрывает тему.
Что делать:Если всё ядро сосредоточено в первом блоке — распределить смысл по другим разделам. Например, вынести «Стоимость продвижения» и «Этапы SEO» в отдельные полноценные H2.
Как использовать эти метрики для улучшения страницы?
Метрики помогают понять, где страница уступает рынку: в ширине раскрытия, глубине проработки или архитектуре структуры.
Что делать:Улучшать страницу через: расширение тематического охвата, усиление детализации, добавление новых смысловых блоков, а не через механическое увеличение объёма текста.
Почему в таблице нет словоформ одного и того же слова?
В анализе используется лемматизация — приведение слов к начальной форме. Это означает, что «уборка», «уборки», «уборке», «уборку» считаются одним термином — «уборка».
Это необходимо для корректного расчёта TF-IDF и IDF. Если учитывать словоформы отдельно, частота одного и того же смысла дробится, статистика искажается, а тематическое ядро размывается.
Без лемматизации система воспринимала бы «уборка» и «уборки» как разные слова, хотя по смыслу это один и тот же термин.
Сервис использует морфологический анализ, приводя каждое слово к нормальной форме. Это позволяет анализировать именно смысловые единицы, а не поверхностные словоформы.
В результате формируется чистая и устойчивая модель ниши, а показатели релевантности рассчитываются корректно.
Что делает опция «Игнорировать скрытые блоки»?
Опция позволяет исключить из анализа текст, который скрыт на странице: вкладки (tabs), аккордеоны, выпадающие блоки, а также элементы со стилями display:none, visibility:hidden и аналогичными.
Такой контент технически присутствует в HTML, но пользователь его не видит сразу при загрузке страницы.
🎯 Зачем это нужно
Поисковые системы учитывают скрытый текст слабее, чем основной видимый контент.
Если не исключать скрытые блоки:
- искусственно увеличивается объём текста страницы
- размывается тематическое ядро
- искажается TF-IDF и структура смыслов
🧠 Как система определяет скрытый текст
Сервис проверяет не только сам элемент, но и всю цепочку родителей. Если хотя бы один из родителей скрыт — весь вложенный текст считается скрытым.
📦 Пример 1 — блок учитывается
<div>
<p>Продвижение сайтов под ключ</p>
</div>
👉 Текст учитывается, так как блок видимый.
🚫 Пример 2 — блок игнорируется
<div style="display:none">
<p>Скрытый SEO текст</p>
</div>
👉 Весь текст внутри полностью исключается при включённой опции.
🔗 Пример 3 — вложенность (важно)
<div class="tabs hidden">
<div>
<p>Контент внутри таба</p>
</div>
</div>
👉 Даже если у вложенного блока нет стиля скрытия, он всё равно игнорируется, потому что родитель скрыт.
🔘 Пример 4 — кнопка «Показать ещё»
<button>Показать ещё</button>
<div style="display:none">
<p>Дополнительный текст</p>
</div>
👉 Несмотря на наличие кнопки, текст считается скрытым, потому что изначально он не отображается на странице.
Сервис анализирует HTML в исходном состоянии, без выполнения JavaScript.
⚠ Важный момент
Даже если пользователь может открыть блок (клик, таб, аккордеон), для анализа он всё равно считается скрытым, если при загрузке страницы он не виден.
🎯 Что происходит при включении опции
- скрытый текст не участвует в TF-IDF
- анализ строится только на видимой части страницы
- при этом считается доля скрытого контента (hidden ratio)
📊 Почему это важно
Скрытый контент:
- влияет на SEO слабее
- может искусственно раздувать текст страницы
- искажает реальную структуру контента
При этом система всё равно:
- учитывает общий объём скрытого контента
- показывает предупреждение, если его слишком много
📊 Когда стоит включать
- при анализе посадочных страниц (лендингов)
- когда много FAQ, табов или аккордеонов
- если нужно получить максимально «чистую» модель текста
⚠ Когда можно оставить выключенным
- если анализируется весь HTML как есть
- если важно учитывать весь текст, включая скрытые блоки
Проще говоря:
- включено → анализ только видимого контента
- выключено → анализ всего HTML, включая скрытые блоки